В предыдущем посте был сделан обзор платформы Hadoop, рассмотрена структура экосистемы Hadoop.
Ниже разберем основные концепции, лежащие в основе HDFS, и архитектуру распределенной файловой системы HDFS.
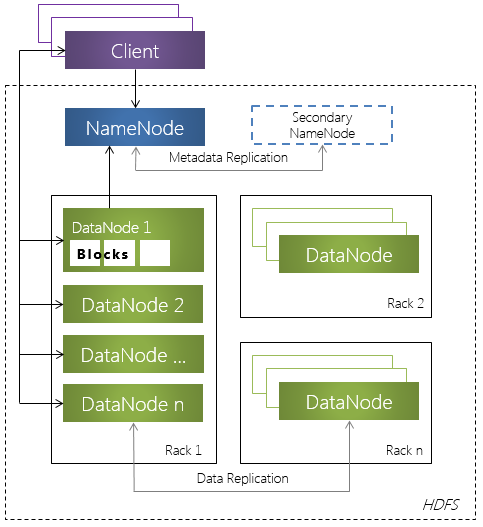
Одним из ключевых компонентов платформы Hadoop является файловая система HDFS.
Hadoop Distributed File System (HDFS) - распределенная
файловая система, которая обеспечивает высокоскоростной доступ к данным приложения.
Концепции и структура HDFS
HDFS является иерархической файловой системой. Таким образом, в HDFS имеется поддержка
вложение каталогов. В каталоге может располагаться ноль или более файлов, а также
любое количество подкаталогов.
HDFS состоит из следующих обязательных компонентов:
- Узел имен (NameNode) – программный код, выполняющийся, в общем случае, на выделенной машине экземпляра HDFS и отвечающий за файловые операции (работу с метаданными);
- Узел данных (DataNode) – программный код, как правило, выполняющийся выделенной машине экземпляра HDFS и отвечающий за операции уровня файла (работа с блоками данных).
Hadoop содержит единственный узел типа NameNode и произвольное количество узлов
типа DataNode.
Основные концепции, заложенные при проектировании HDFS, и архитектурные решения,
применяемые для реализации этих концепций, приведены ниже:
-
Объем данных
HDFS не должна иметь достижимых в обозримом будущем ограничений на объем хранимых данных.Архитектурные решения:
- HDFS хранит файлы поблочно. Блоки в HDFS распределены между узлами данных вычислительного кластера. Все блоки (кроме последнего блока файла) имеют одинаковый размер, кроме того блок может быть размещён на нескольких узлах.
-
Отказоустойчивость
HDFS расценивает выход из строя узла данных как норму, а не как исключение (и, действительно, вероятность выхода хотя бы одного узла из тысячи даже на надежном физическом оборудовании существенная).Архитектурные решения:
- Для обеспечения отказоустойчивости все данные в HDFS реплицируются настраиваемое количество раз. Подробнее о том, как обеспечивается репликация в Hadoop-кластере на уровне файловой системе, описано в разделе «Файловые операции и репликация».
- Защита от копирования поврежденных данных решена с помощью хранения контрольных сумм в отдельном скрытом файле.
- Копирование метаданных с помощью вторичного узла имен.
-
Самодиагностика
Диагностика исправности узлов в Hadoop-кластере не должна требовать дополнительного администрирования.Архитектурные решения:
- Каждый узел данных через определенные интервалы времени отправляет диагностические сообщения узлу имен (узлы данных подробно будут рассмотрены ниже).
- Логгирование операций над файлами в специальный журнал узла имен.
-
Производительность
В апреле 2008 года Hadoop побил мировой рекорд производительности в стандартизованном тесте производительности по сортировке данных — 1 ТБайт был обработан за 309 сек. на кластере из 910 узлов [22].Архитектурные решения:
- Принцип «один раз записать – много раз прочитать» (Write-once and read-many, WORM) полностью освобождает систему от блокировок типа «запись-чтение». Избавиться от конфликтов множественной записи проектировщики решили, разрешив запись в файл в одно время только одному процессу.
- HDFS оптимизирован под потоковую передачу данных.
- Снизить нагрузку на каналы передачи данных (а именно эти каналы чаще всего являются узким местом в распределенных средах), а также более рационально использовать место на жестких дисках позволило сжатие данных.
- Репликация происходит в асинхронном режиме.
- Хранение всех метаданных узла NameNode в оперативной памяти.
Узлы имен
Узел имен (NameNode) представляет собой программный
код, выполняющийся, в общем случае, на выделенной машине экземпляра HDFS и отвечающий
за файловые операции, такие как открытие и закрытие файлов, создание и удаление
каталогов. Кроме того, NameNode отвечает за:
- управление пространством имен файловой системы;
- управление доступом со стороны внешних клиентов;
- соответствие между файлами и реплицированными на узлах данных блоками.
Hadoop содержит единственный узел типа NameNode. Что порождает уязвимость* всего
кластера, вызванную выходом узел типа NameNode (единичная точка отказа). HDFS поддерживает
вторичный узел имен – Secondary NameNode. Часто это факт является причиной заблуждения,
что при отказе первичного узла имен, его автоматически заменит вторичный узел имен.
На самом деле поддержки автоматического восстановления кластера после отказа первичного
узла NameNode в версии 1.0.0 нет.
Вторичный узел имен выполняет следующие функции:
- копирует образ HDFS (расположенный в файле FsImage) и лог транзакций операций с файловыми блоками (EditLog) во временную папку;
- применяет изменения, накопленные в логе транзакций к образу HDFS;
- записывает новый образ FsImage на узел NameNode, после чего происходит очистка EditLog.
Узлы данных
Узел данных (DataNode), как и узел NameNode, также представляет собой программный
код, выполняющийся, как правило, на выделенной машине экземпляра HDFS и отвечающий
за операции уровня файла, такие как: запись и чтение данных, выполнение команд создания,
удаления и репликации блоков, полученные от узла NameNode.
Кроме того, узел DataNode отвечает за:
- периодическую отправку сообщения о состоянии (heartbeat-сообщения);
- обработку запросов на чтение и запись, поступающие от клиентов файловой системы HDFS, т.к. данные проходят с остальных машин кластера к клиенту мимо узла NameNode.
Клиенты HDFS
Клиенты представляют собой программных клиентов, работающих с файловой системой.
В роли клиента может выступать любое приложение или пользователь, взаимодействующий
через специальный API с файловой системой HDFS.
Для клиента HDFS выглядит как обычная** файловая система – иерархия каталогов с вложенными
в них подкаталогами и файлами. Как и в файловых системах общего назначения, клиенту,
при наличии достаточных прав, разрешены следующие операции: создание, удаление,
переименование, перемещение. Вышеназванные операции применимы к каталогам и файлам.
Наиболее существенное отличие работы клиента с файловой системой HDFS от работы
с файловой системой общего назначение – это то, что при создании файла клиент может
явно указать размер блока файла (по умолчанию 64 Мб) и количество создаваемых реплик
(по умолчанию значение равно 3-ем).
Взаимодействие компонентов HDFS
Взаимодействие узлов имен, узлов данных и клиентов осуществляется по протоколам,
основывающимся на протоколе TCP/IP.
Клиент создает соединение через специально сконфигурированный
для взаимодействия TCP-порт на целевом узле NameNode. Взаимодействия клиента с узлом
NameNode происходит по протоколу ClientProtocol. Узлы DataNode взаимодействуют с
узлом DataNode, используя протокол DataNode Protocol [6].
И ClientProtocol, и DataNode Protocol «обернуты» в Remote Procedure Call (RPC).
Узел NameNode никогда не инициализирует вызовы RPC – он только отвечает на RPC-вызовы
узлов DataNode и клиентов [6].
Файловые операции и репликация
Набор допустимых файловых операций в распределенной файловой системе HDFS схож с
набором файловых операций в «локальных» файловых системах за исключением операции
модификации файла – модификация в HDFS не поддерживается по причинам, связанным
с архитектурными особенностями (в том числе и вопросами производительности и блокировок)
этой файловой системы.
За все файловые операции отвечает узел NameNode. Операции с конкретными файлами
находятся в зоне ответственности узла DataNode, на котором эти файлы находятся.
Подробнее о функциях, выполняющихся на узлах имен и узлах данных будет рассказано ниже.
Интересные архитектурные решения были найдены для создания файлов.
Изначально клиент
кэширует необходимую для записи информацию где-то во временном (или постоянном –
его дело) хранилище. После того, как объём информации достигает предполагаемого
клиентом размера блока в HDFS, клиент отправляет на узел NameNode запрос на создание
файла, опционально указав размер блока для создаваемого файла и количество реплик.
Узел NameNode отвечает клиенту, отправив в ответ идентификатор узла данных и блок
назначения, на который будет вестись запись. Также узел NameNode уведомляет другие
узлы DataNode, на которые будут писаться реплики файлового блока. После начала передачи
файлового потока узлу DataNode, принимающий узел начинает автоматическую ретрансляцию
файлового блока на другие узлы реплики. Окончание записи файлового блока фиксируется
в журнале узла имен.
Все файловые блоки реплицируются указанное клиентом при создании раз. Вторая реплика
файлового блока хранится на другом узле, а третья – на узле, расположенном на другой
стойке. Расположение следующих реплик вычисляется произвольно.
Если узел NameNode не принимает от узла DataNode heartbeat-сообщений, то узел имен
помечает это узел DataNode как «умерший» и реплицирует данные, хранящиеся на «умершем»
узле из «оставшихся в живых» копий.
Ограничения HDFS
Файловая система HDFS обладает следующими ограничениями:
- узел имен NameNode является единой точкой отказа;
- отсутствие полноценной репликации Secondary NameNode;
- отсутствие возможности дописывать или оставить открытым для записи файлы в HDFS*** (как следствие, в plain Hadoop отсутствует поддержка обновляемых и потоковых данных);
- отсутствие поддержки реляционных моделей данных;
- отсутствие инструментов для поддержки ссылочной целостности данных;
- низкая безопасность данных.
В следующей статье будут рассмотрены основные концепции и архитектура фреймворка распределенных вычислений Hadoop MapReduce.
* Эта уязвимость имеется в релизе 1.0.0 и будет устранена в будущих релизах.
** Под «обычной» файловой системой здесь понимается, что для клиента файловая система
представляет «чистую» абстракцию – клиент ничего не знает о том, как и куда записываются/читаются
файлы, а также о других аспектах функционирования HDFS, связанных с ее распределенным
характером.
*** HBase решает свой класс задач.
Комментариев нет:
Отправить комментарий